

GitHub sparks345 android kv cache global key value cache for android

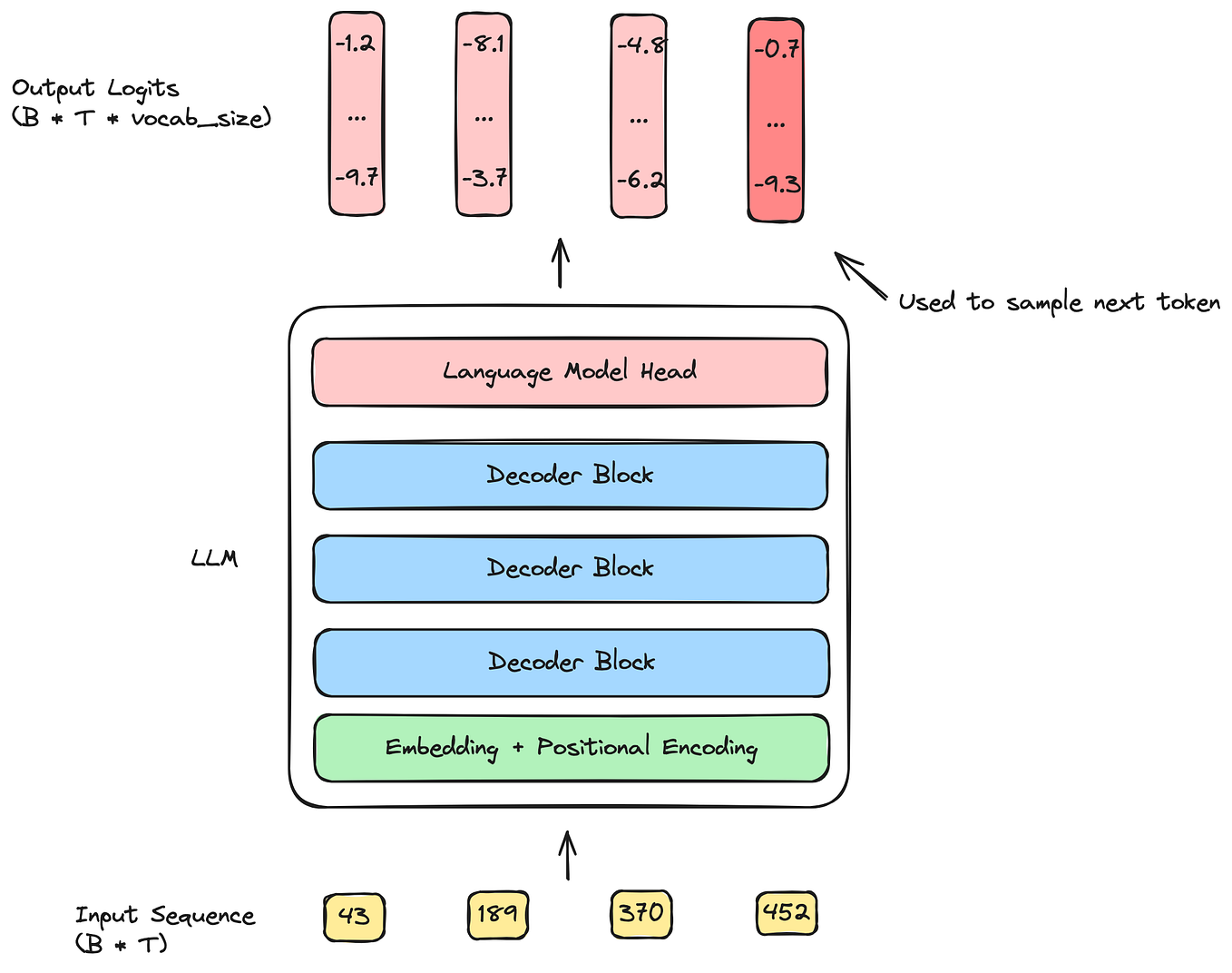
What is the KV cache Matt Log
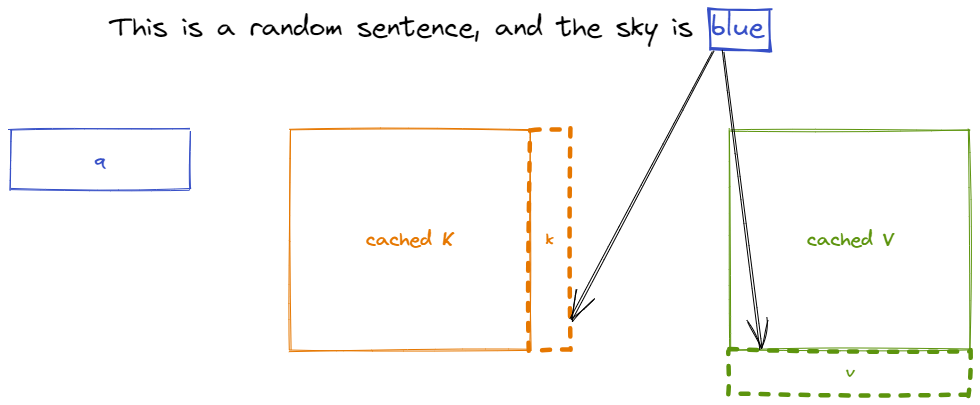
What is the KV cache Matt Log
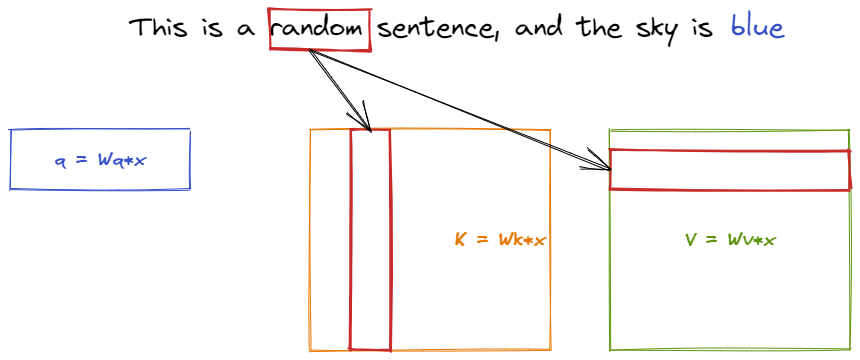
What is the KV cache Matt Log

GEAR An Efficient KV Cache Compression Recipe for Near Lossless

8 bit KV Cache
55+ Images of What Is Kv Cache

Gallery of What Is Kv Cache :
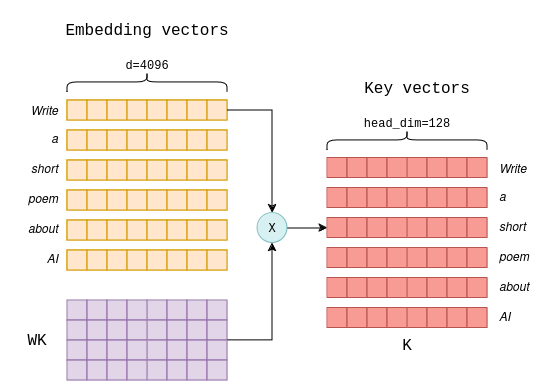
Techniques for KV Cache Optimization in Large Language Models
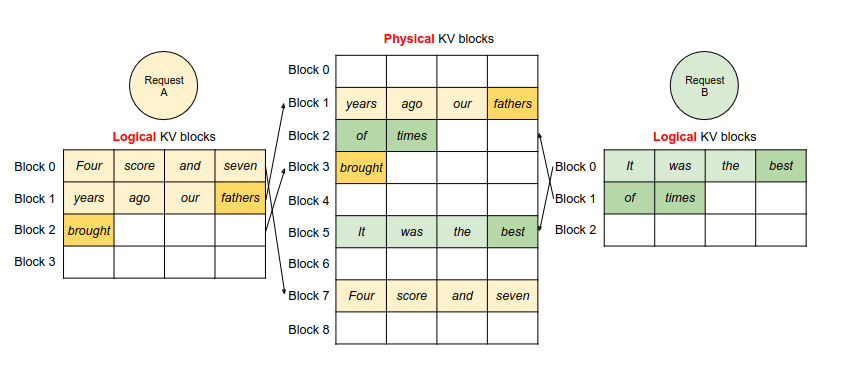
Techniques for KV Cache Optimization in Large Language Models

List Kv cache Curated by Rajoli Manikanta Medium
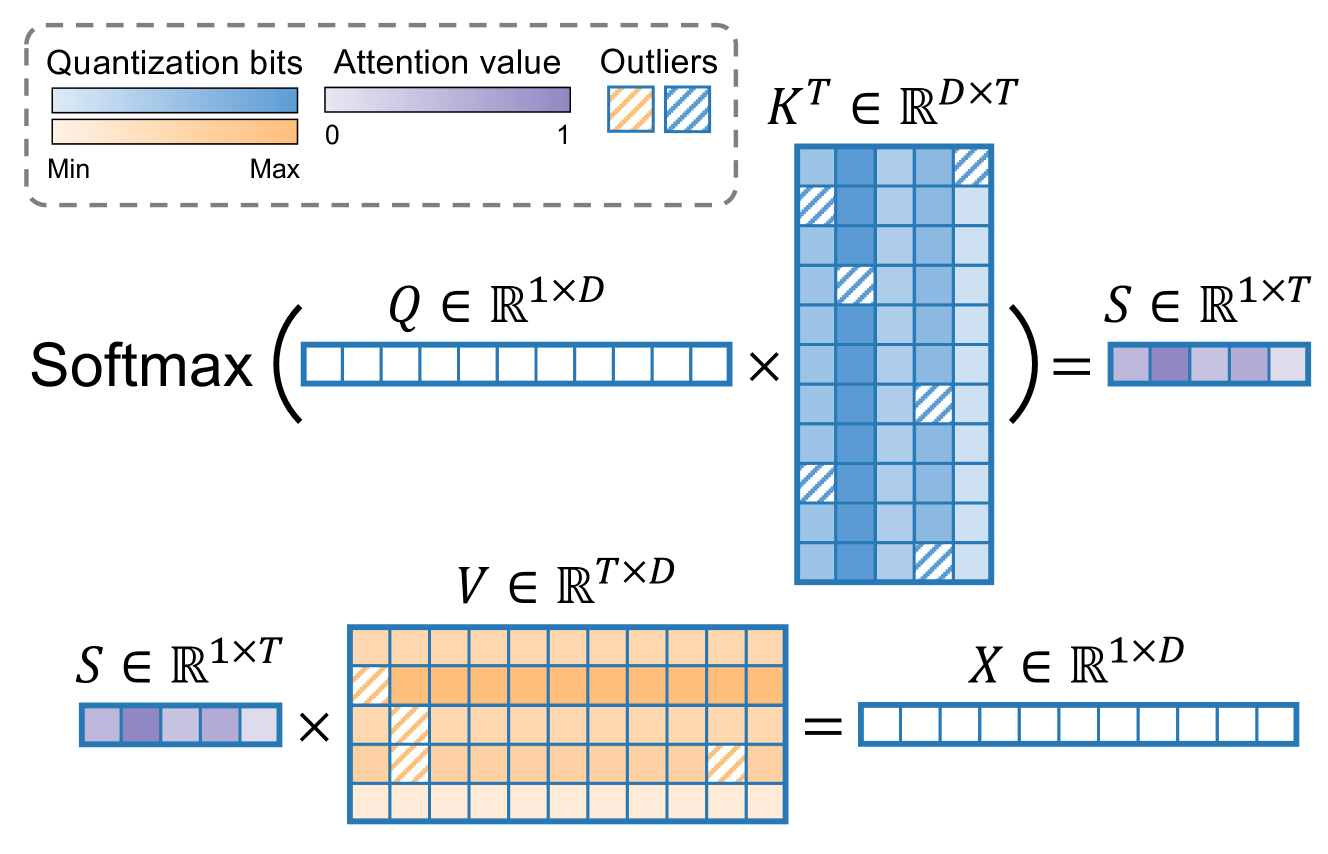
Awesome Efficient LLM kv cache compression md at main 183 horseee Awesome

Awesome Efficient LLM kv cache compression md at main 183 horseee Awesome

Awesome Efficient LLM kv cache compression md at main 183 horseee Awesome
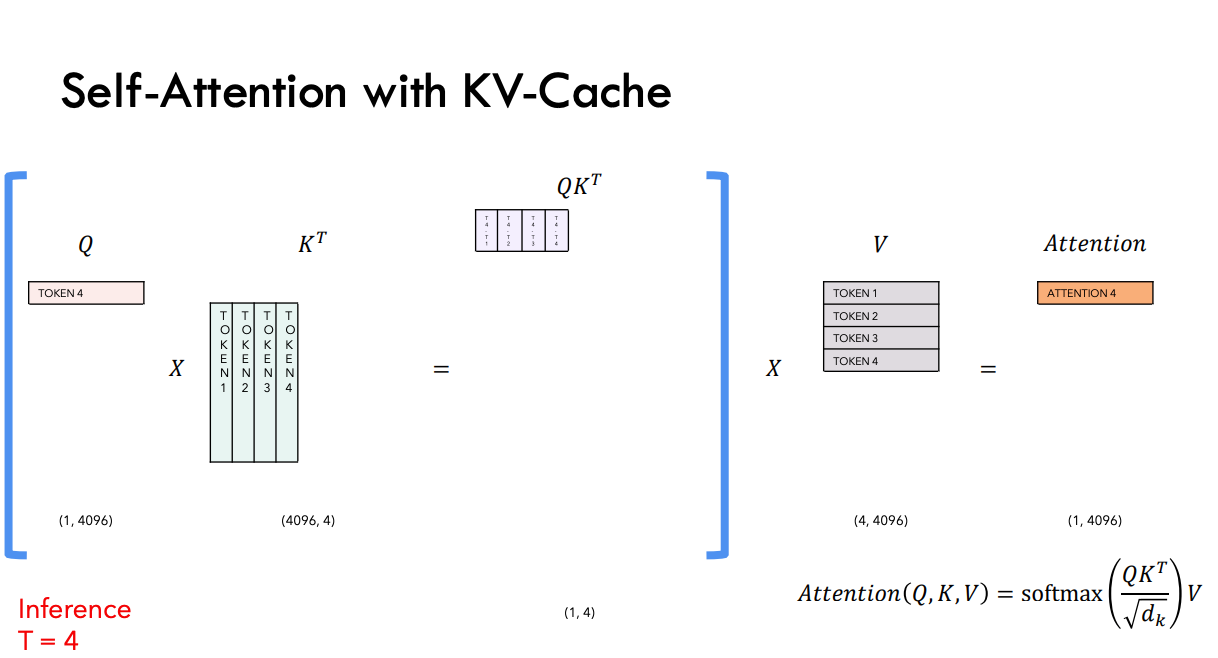
KV Cache in Transformer Inference Ruixiang s blog
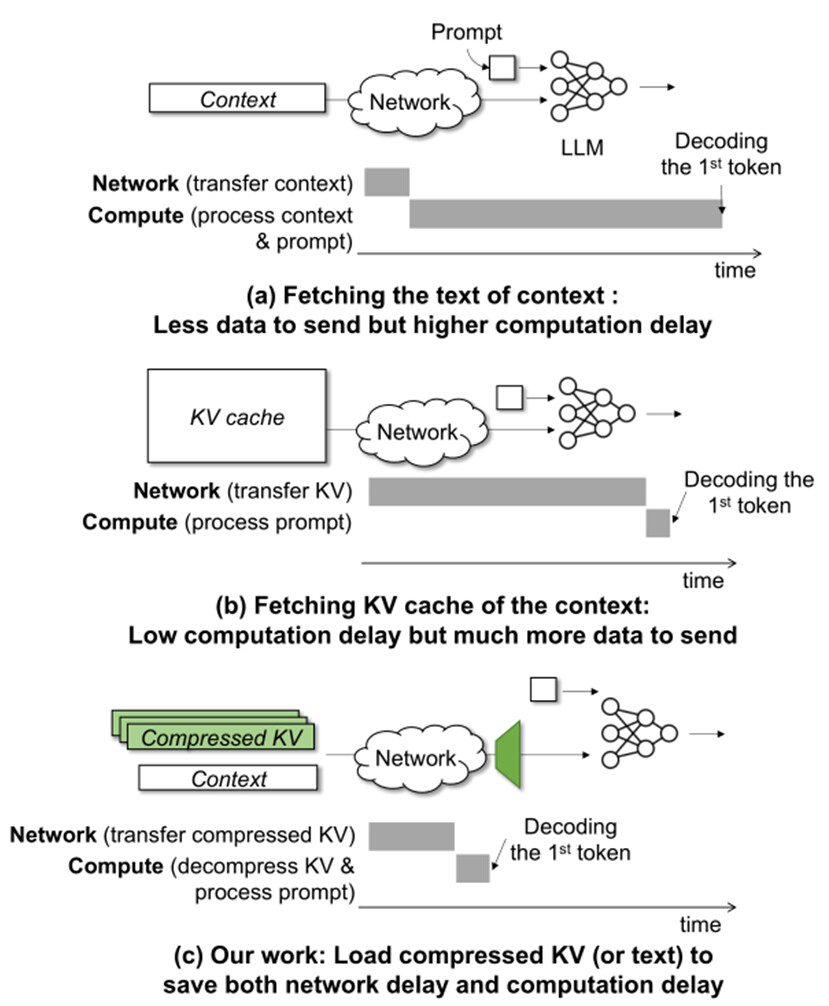
CacheGen KV Cache Compression and Streaming for Fast Large Language
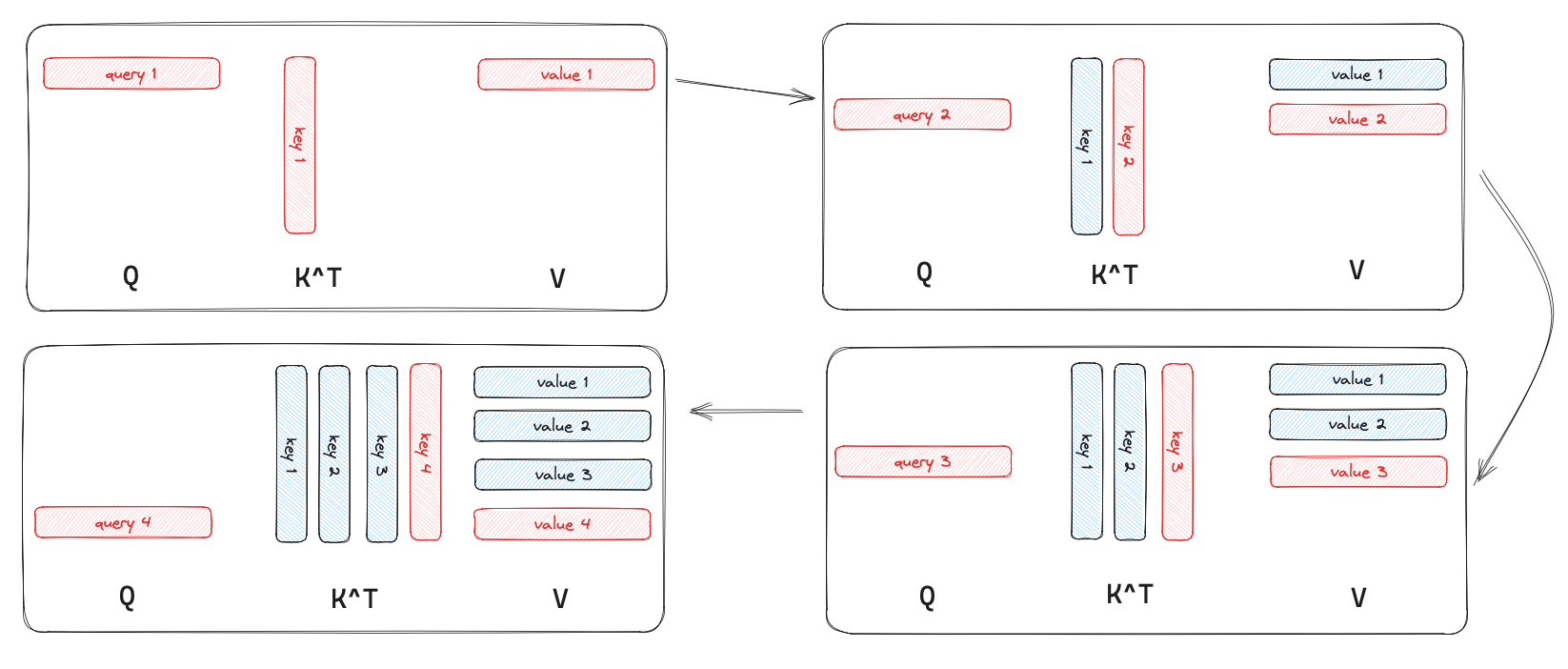
LLM inference optimization KV Cache MartinLwx s Blog
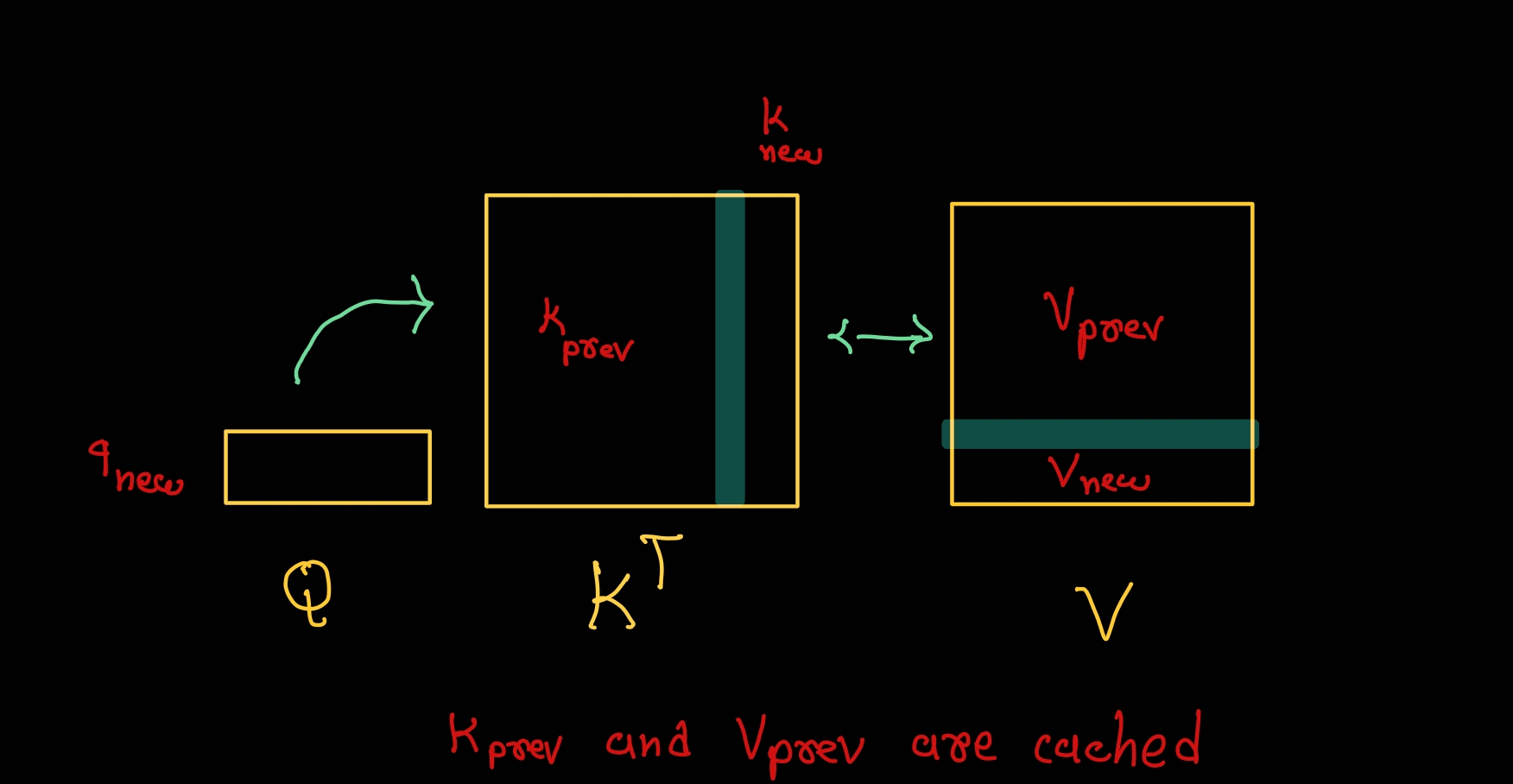
Speeding up the GPT KV cache Becoming The Unbeatable

LLM profiling guides KV cache optimization Microsoft Research

KV Cache Manager The Key Idea Behind It and How It Works HackerNoon

PDF CacheGen KV Cache Compression and Streaming for Fast Large

PDF MiniCache KV Cache Compression in Depth Dimension for Large

KIVI A Plug and Play 2 bit KV Cache Quantization Algorithm without the
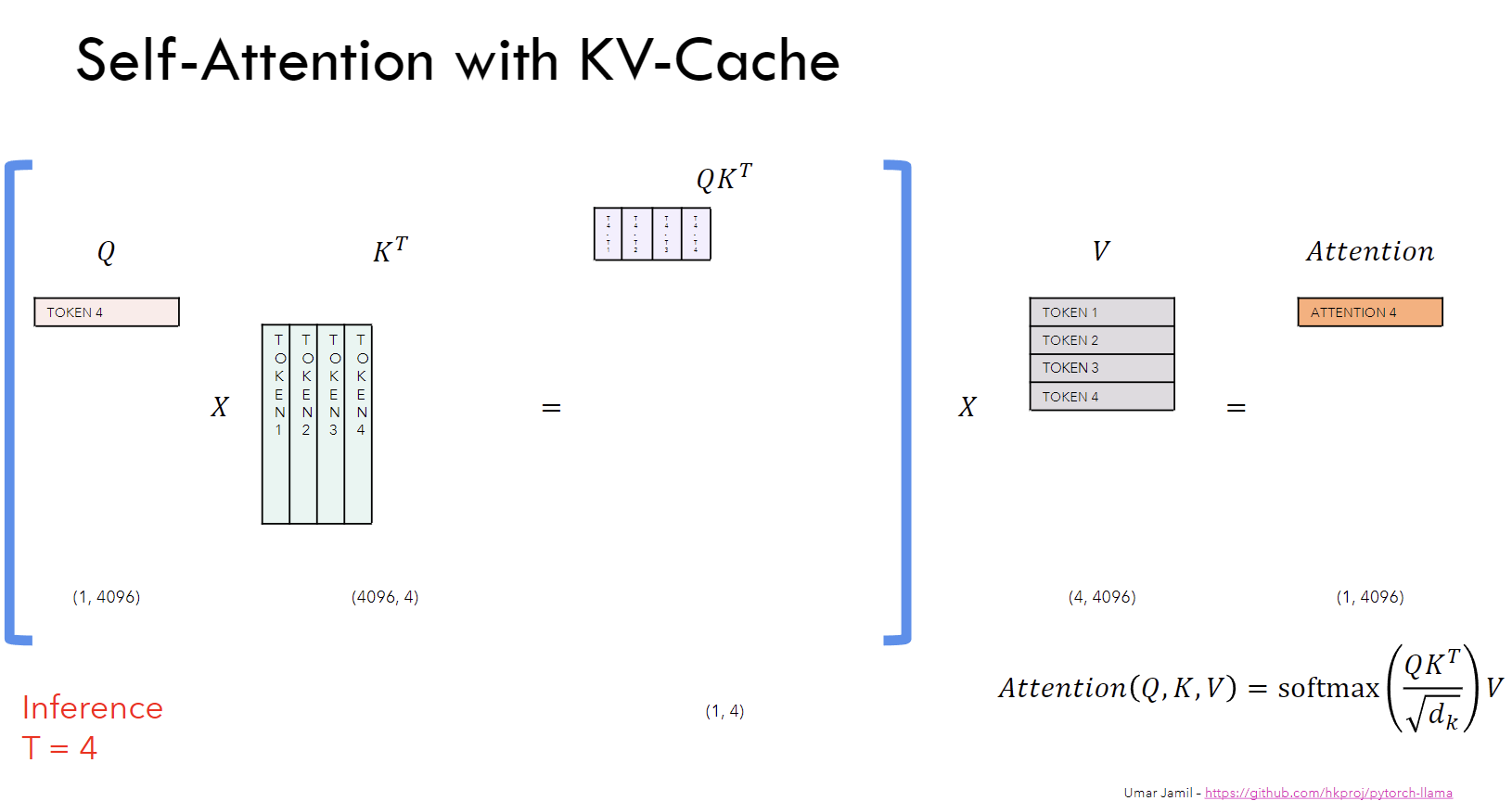
Welcome to my blog Understanding KV Cache
Welcome to my blog Understanding KV Cache

PDF KV Cache A Scalable High Performance Web Object Cache for Manycore

KV Cache Compression But What Must We Give in Return A Comprehensive

KV Cache a stereoplegic Collection
KV Cache a stereoplegic Collection

Figure 2 from Layer Condensed KV Cache for Efficient Inference of Large

PDF Layer Condensed KV Cache for Efficient Inference of Large
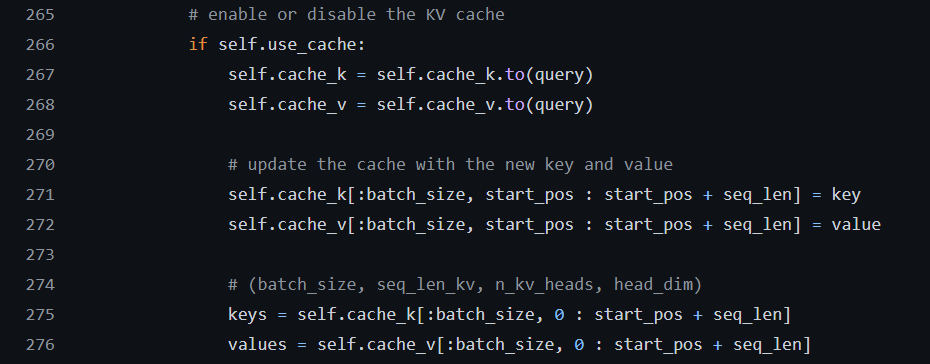
Transformers KV Caching Explained by Jo 227 o Lages Medium
Memory Optimization in LLMs Leveraging KV Cache Quantization for

vAttention Dynamic KV cache Memory Management for Serving LLMs without
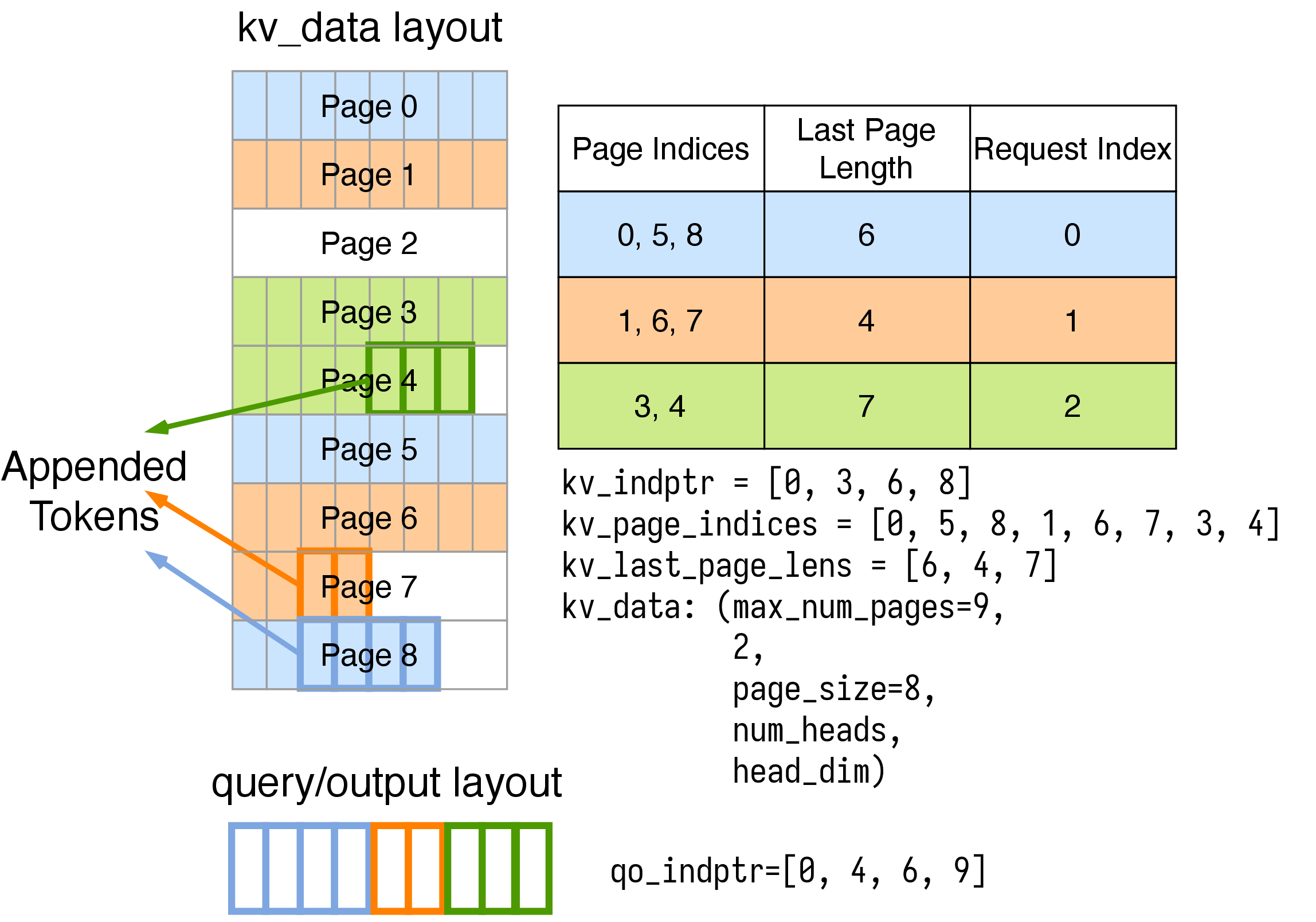
KV Cache Layout in FlashInfer FlashInfer 0 2 1 post1 documentation

KV Cache LLM Bookstall
.png)
KV Cache LLM Bookstall
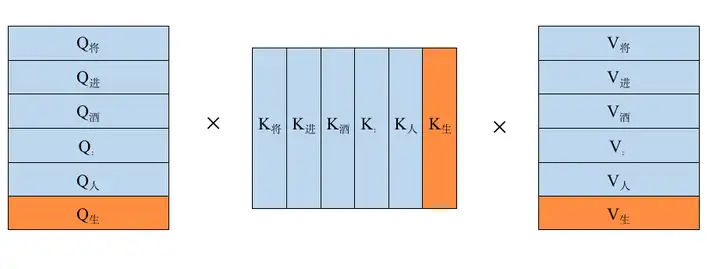
KV Cache LLM Bookstall
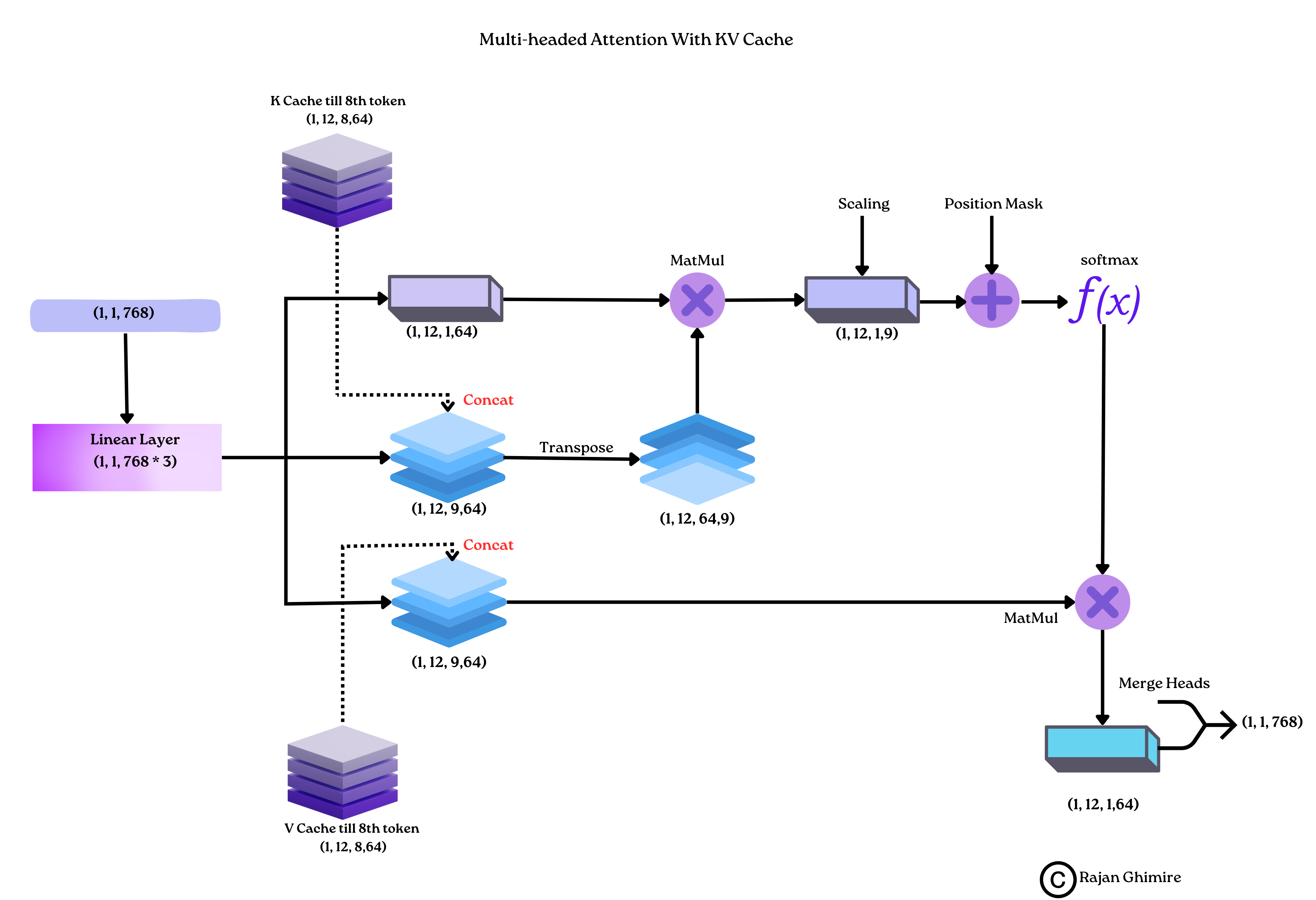
Transformers Optimization Part 1 KV Cache Rajan Ghimire
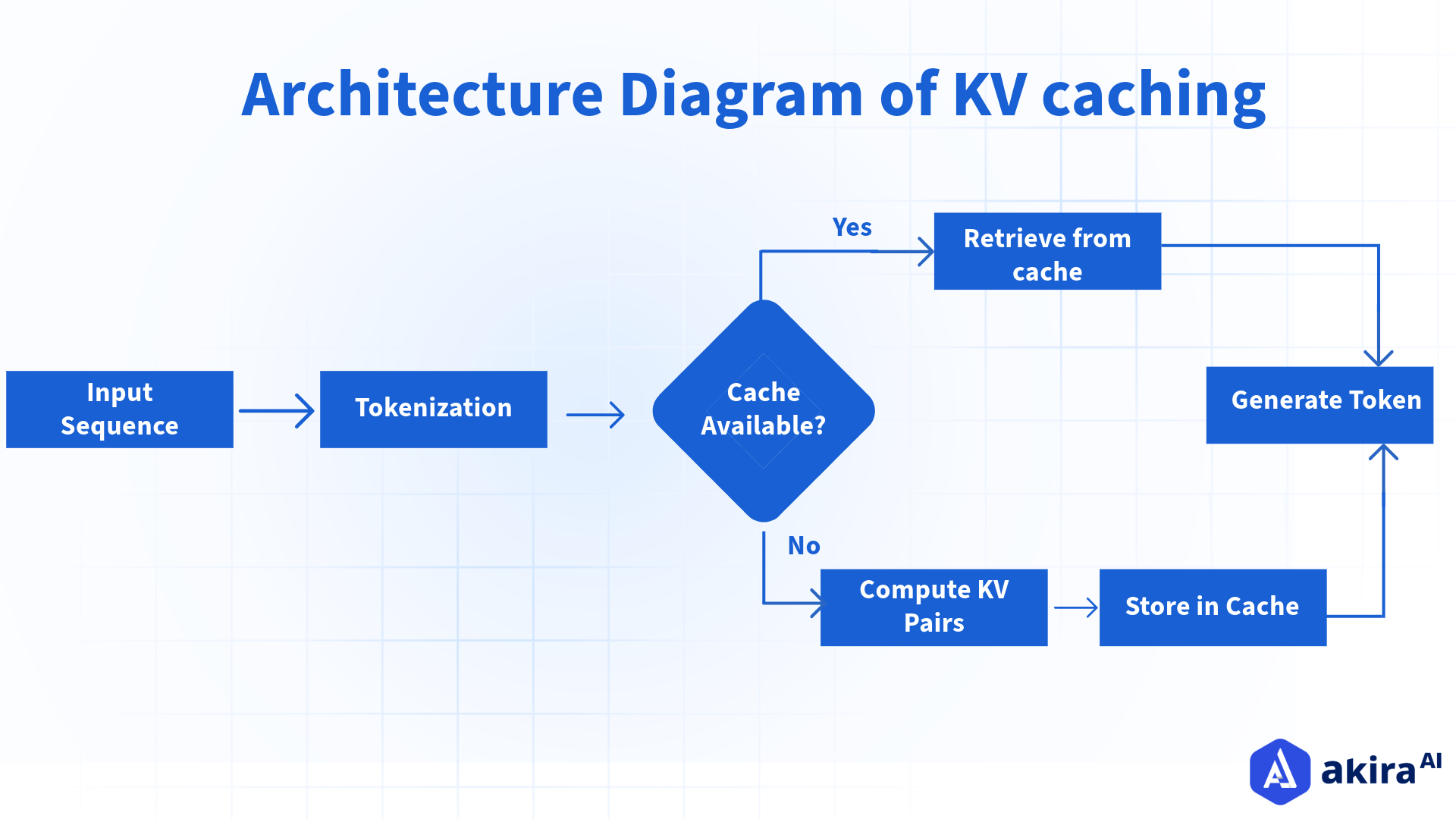
KV Caches and Time to First Token Optimizing LLM Performance
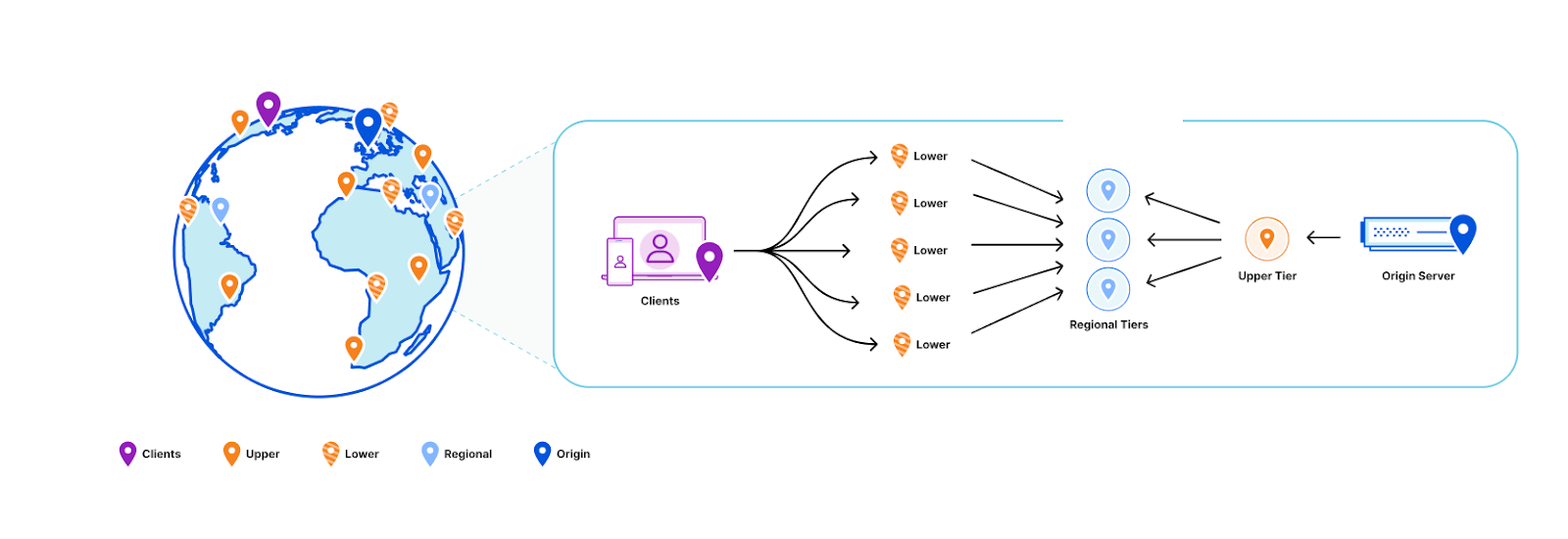
Workers KV is faster than ever with a new architecture Noise

The KV Cache Memory Usage in Transformers YouTube

QA Layer Condensed KV Cache for Efficient Inference of Large Language

MESSAGE
Performance Automatic Prefix Caching When hitting the KV cached
Feature Support for 4 bit KV Cache in paged attention op 183 Issue
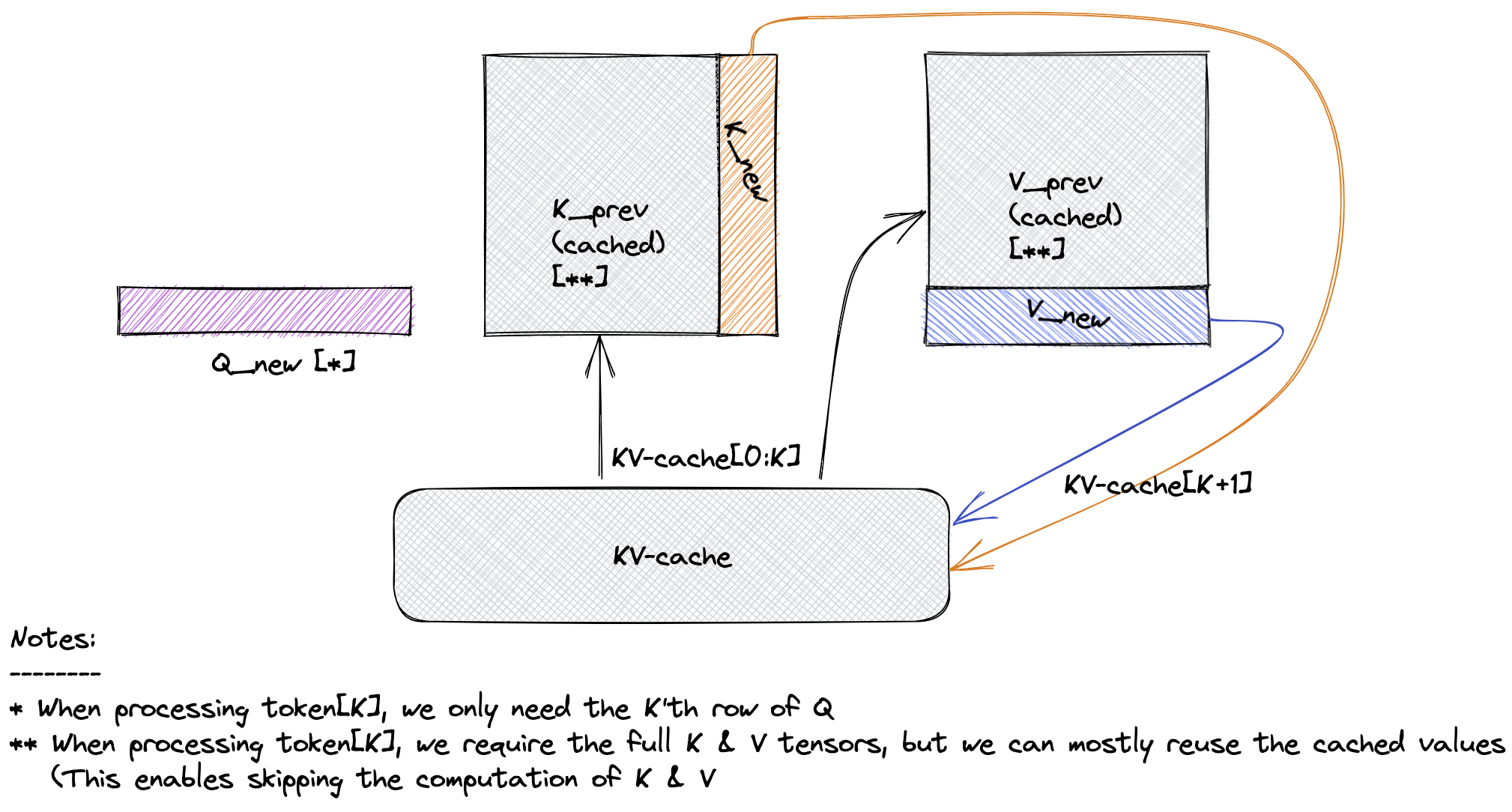
GitHub aju22 LLaMA2 This repository contains an implementation of
Smaller available space for paged KV cache compared with vLLM 183 Issue
Performance Automatic Prefix Caching When hitting the KV cached
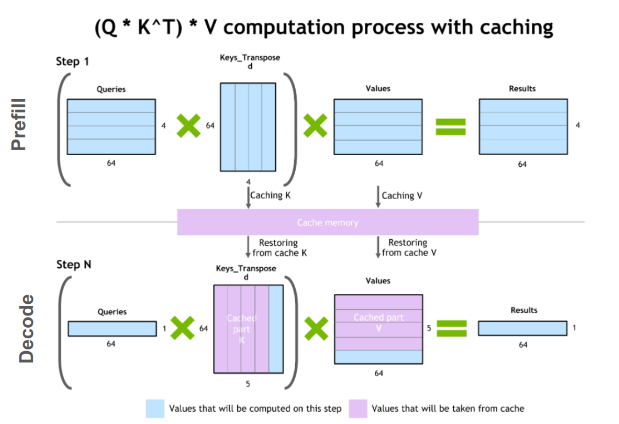
Mastering LLM Techniques Inference Optimization GIXtools
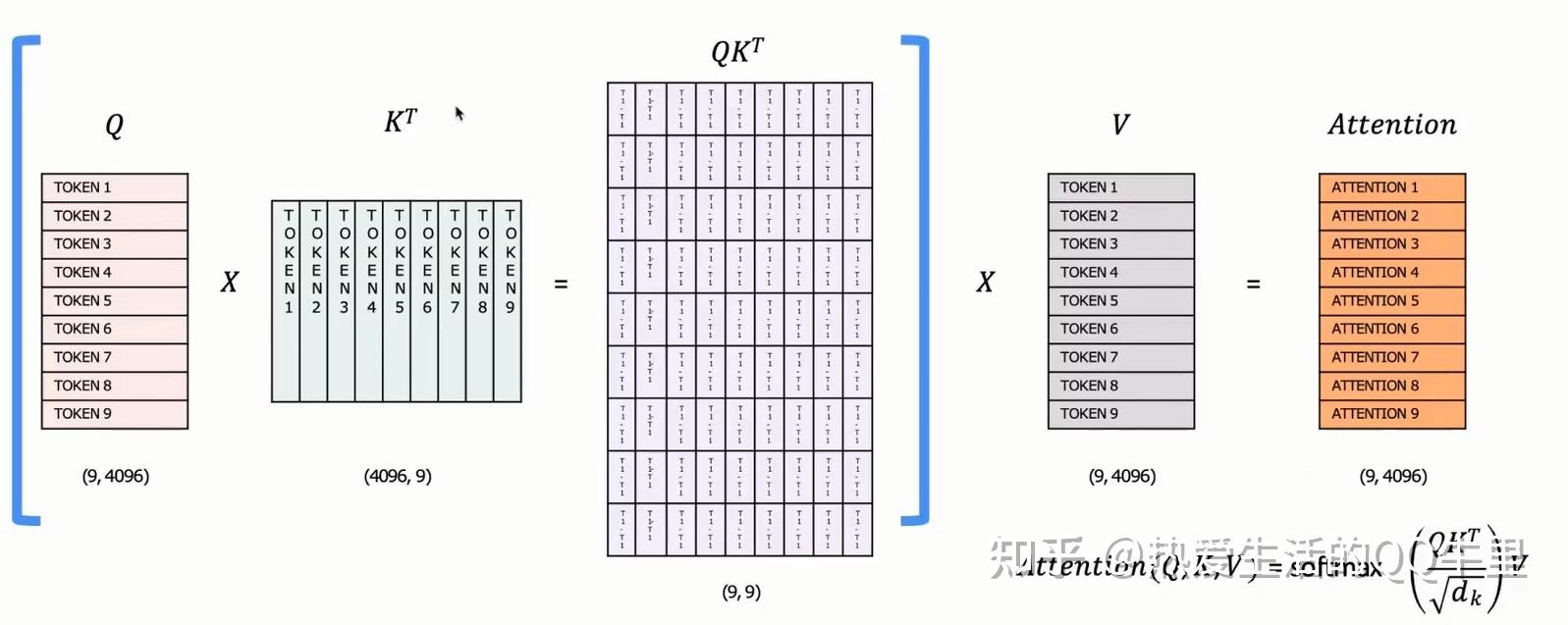
0 LLaMA2 KVcache
LLM KVCache PageAttention FlashAttention MQA GQA
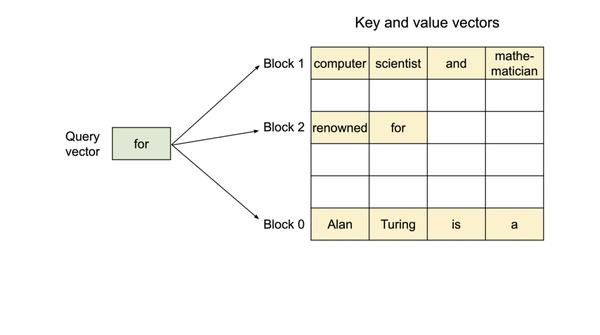
LLM KV Cache
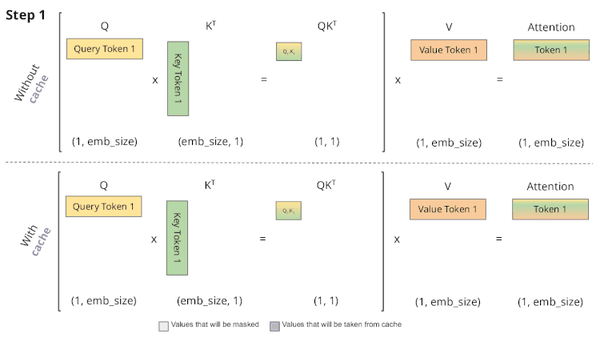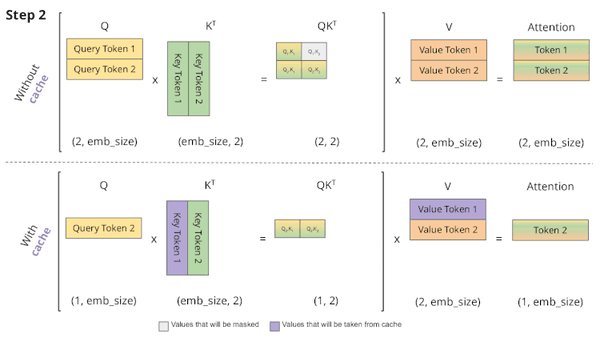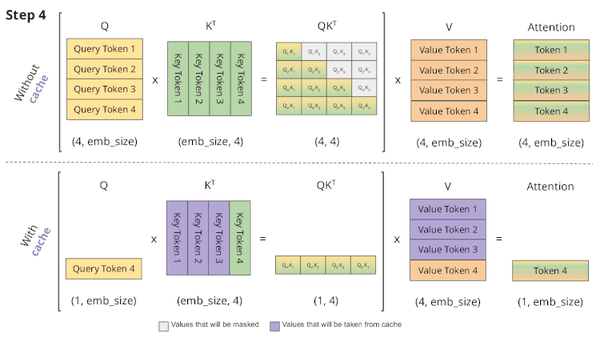
LLM KV Cache StreamingLLM
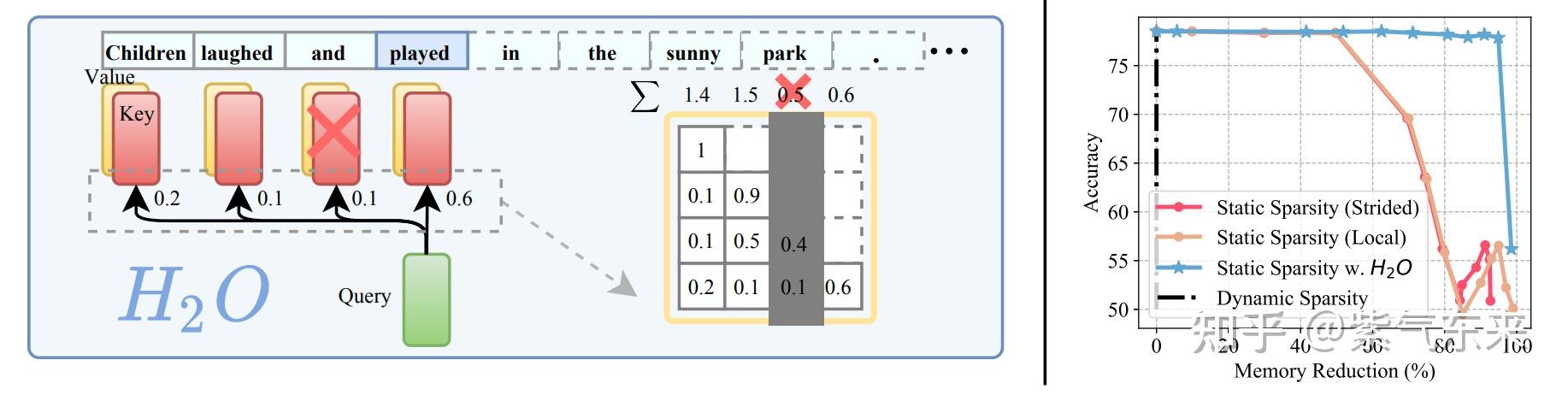
LLM KV Cache StreamingLLM
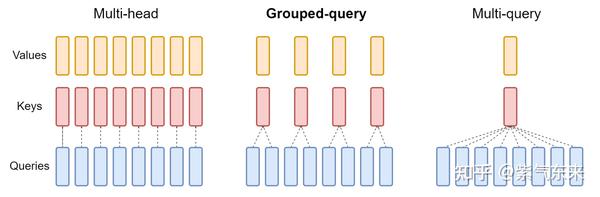
LLM KV Cache StreamingLLM
LLM KV Cache StreamingLLM
LLM KV Cache StreamingLLM
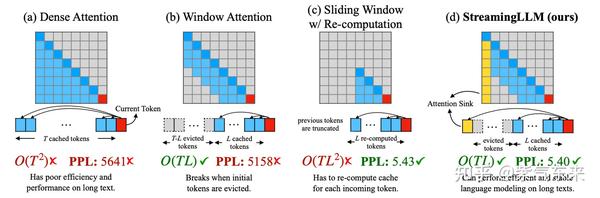
LLM KV Cache StreamingLLM
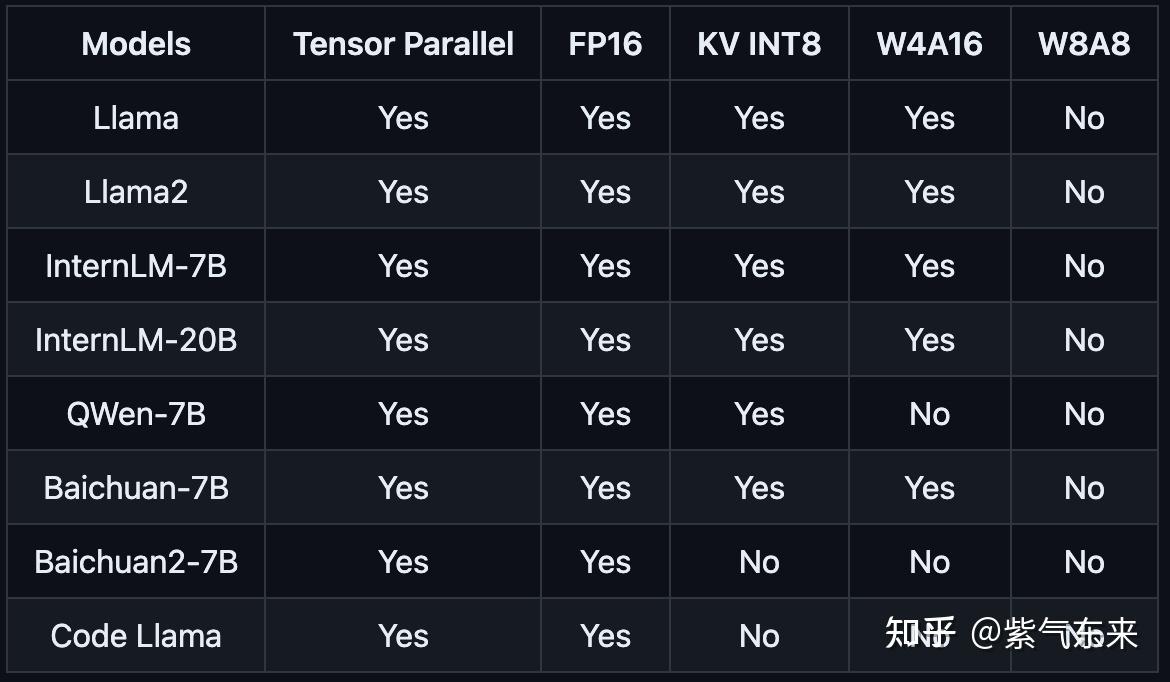
LLM KV Cache StreamingLLM

LLM Inference KV Cache

LLM Inference KV Cache
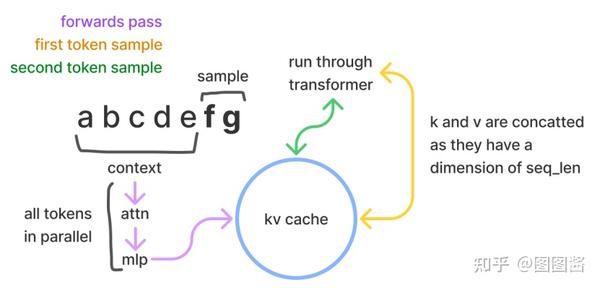
kv kv cache
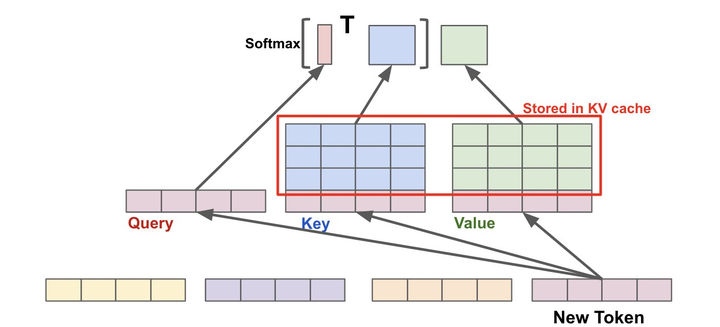
KV Cache

KV cache

KV cache
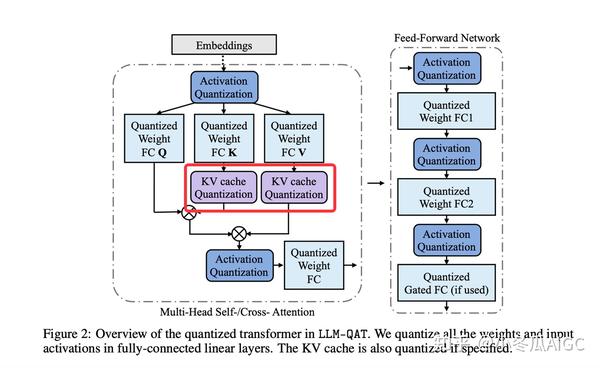
LLM KVCache
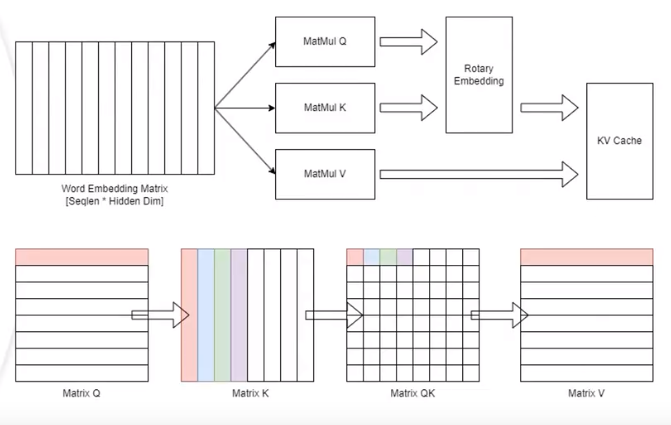
LLM
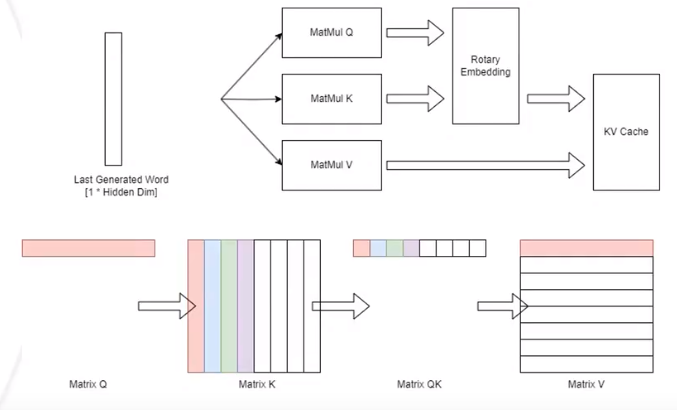
LLM

KV Cache KV Cache

KV Cache KV Cache

transformer KV Cache transformer kv cache CSDN
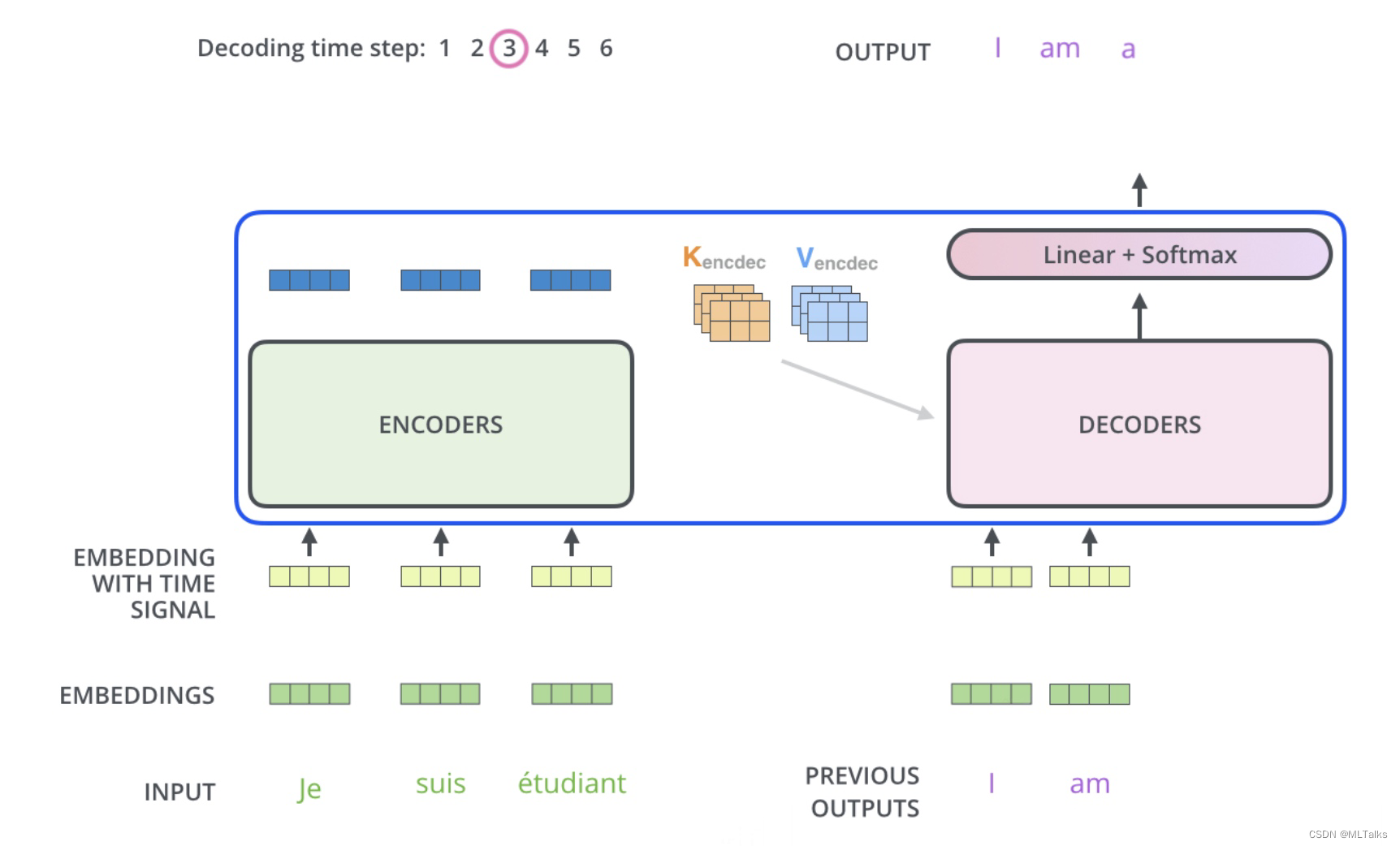
Transformer KV KV Cache CSDN

KV Cache kvcache CSDN

KV Cache Transformer kv cache CSDN

KV Cache kvcache bish CSDN
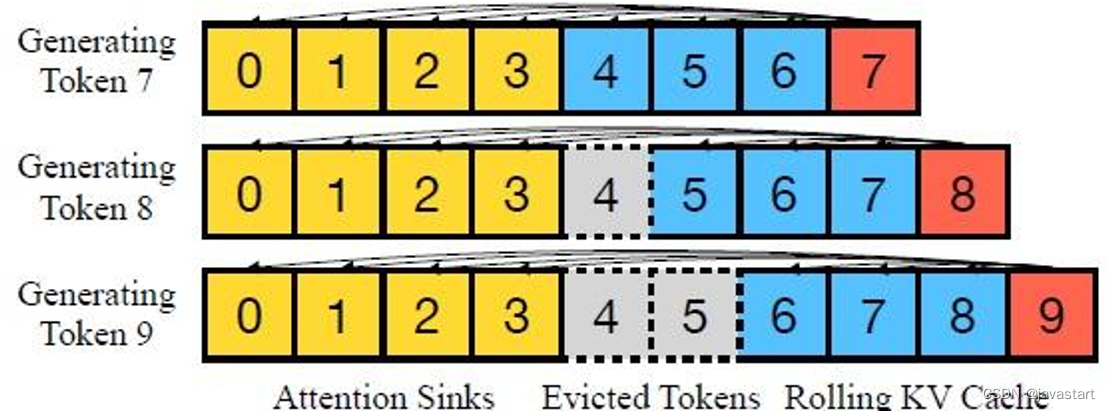
KV Cache kvcache bish CSDN

kvcache kv cache CSDN
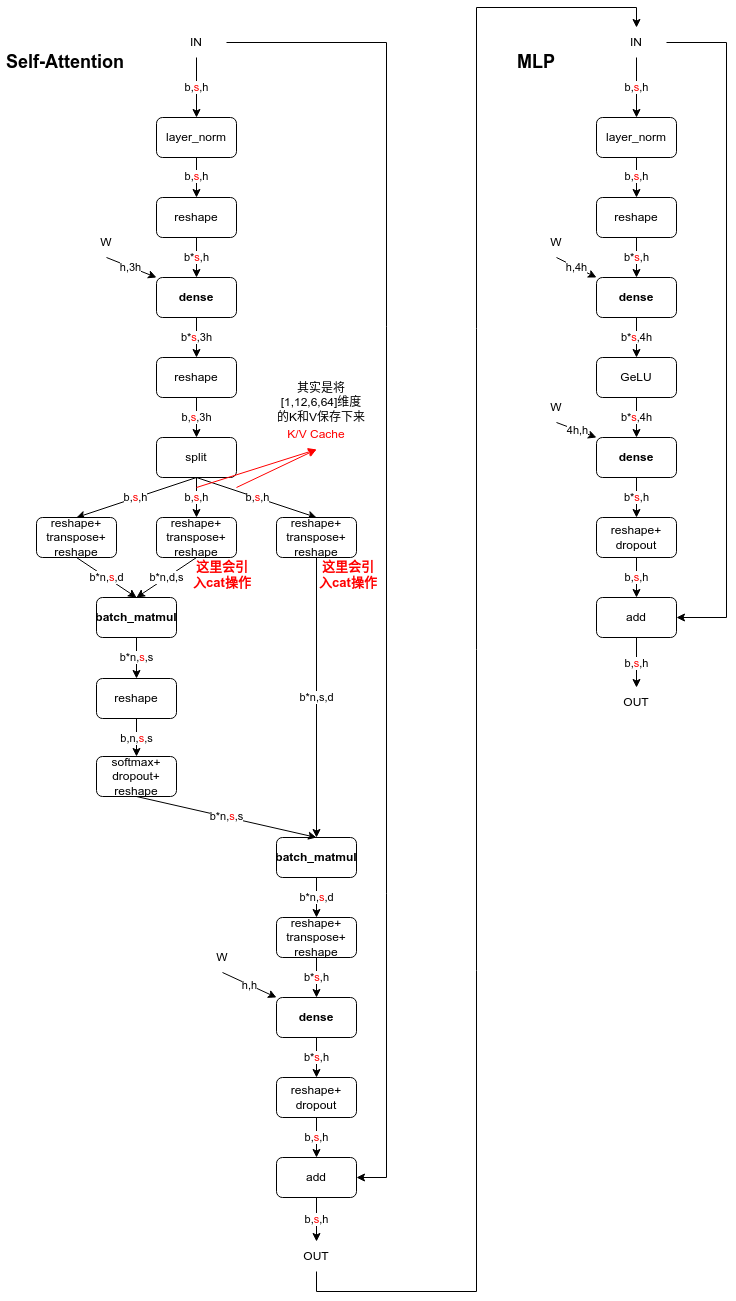
KV Cache CSDN

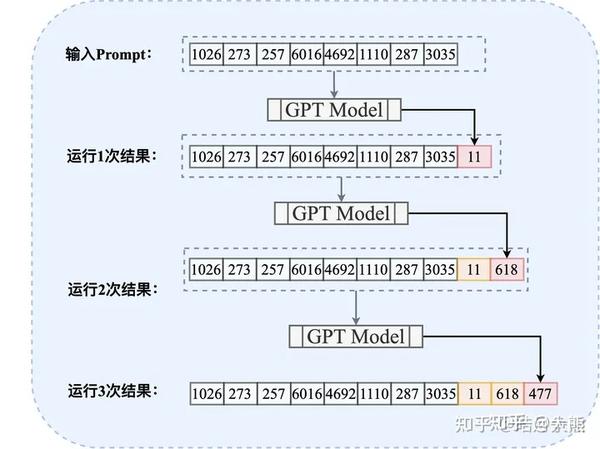
LLM Generate With KV Cache By GPT 2 llm kv cache CSDN
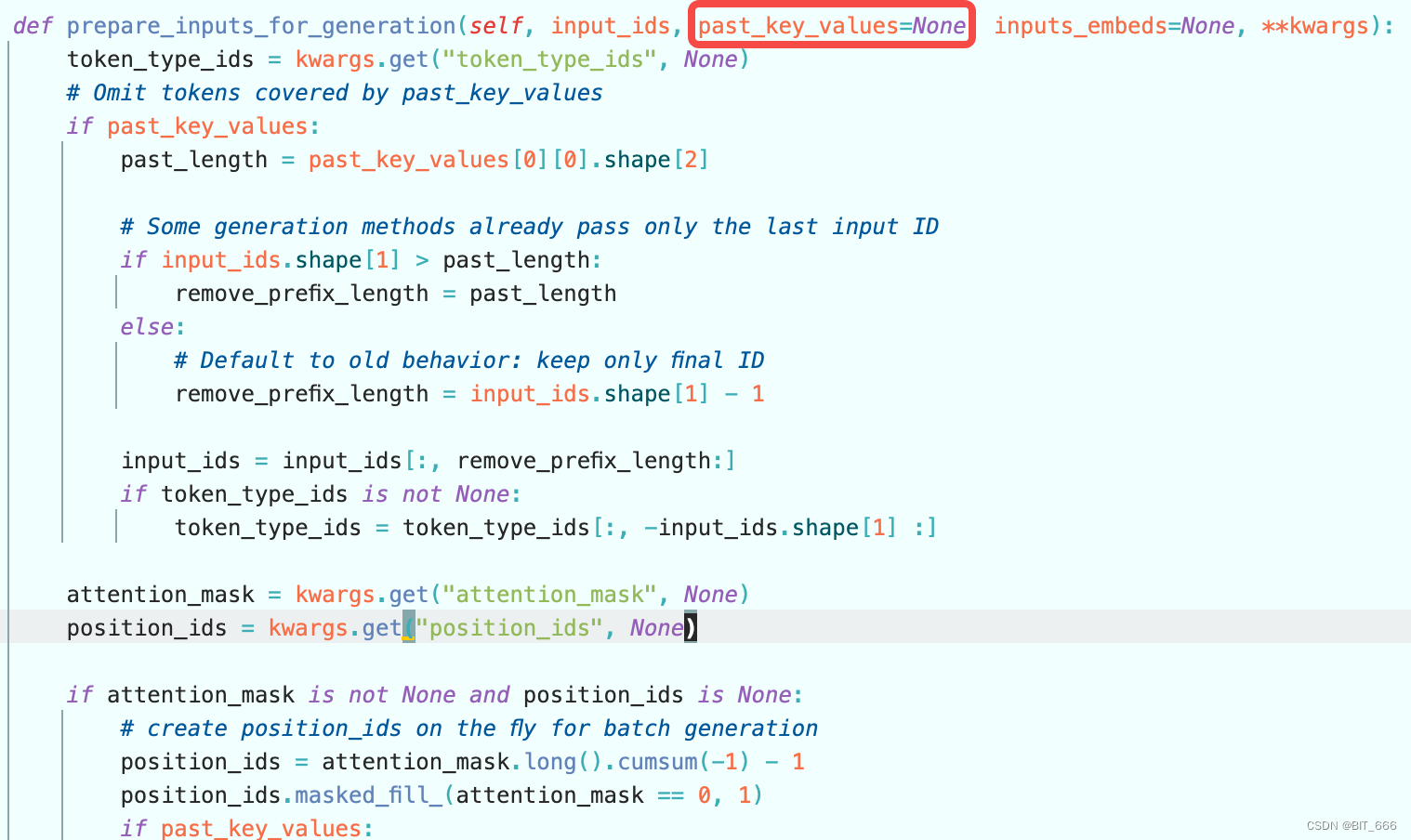
LLM Generate With KV Cache By GPT 2 llm kv cache CSDN

LLM Generate With KV Cache By GPT 2 llm kv cache CSDN

LLM Generate With KV Cache By GPT 2 llm kv cache CSDN
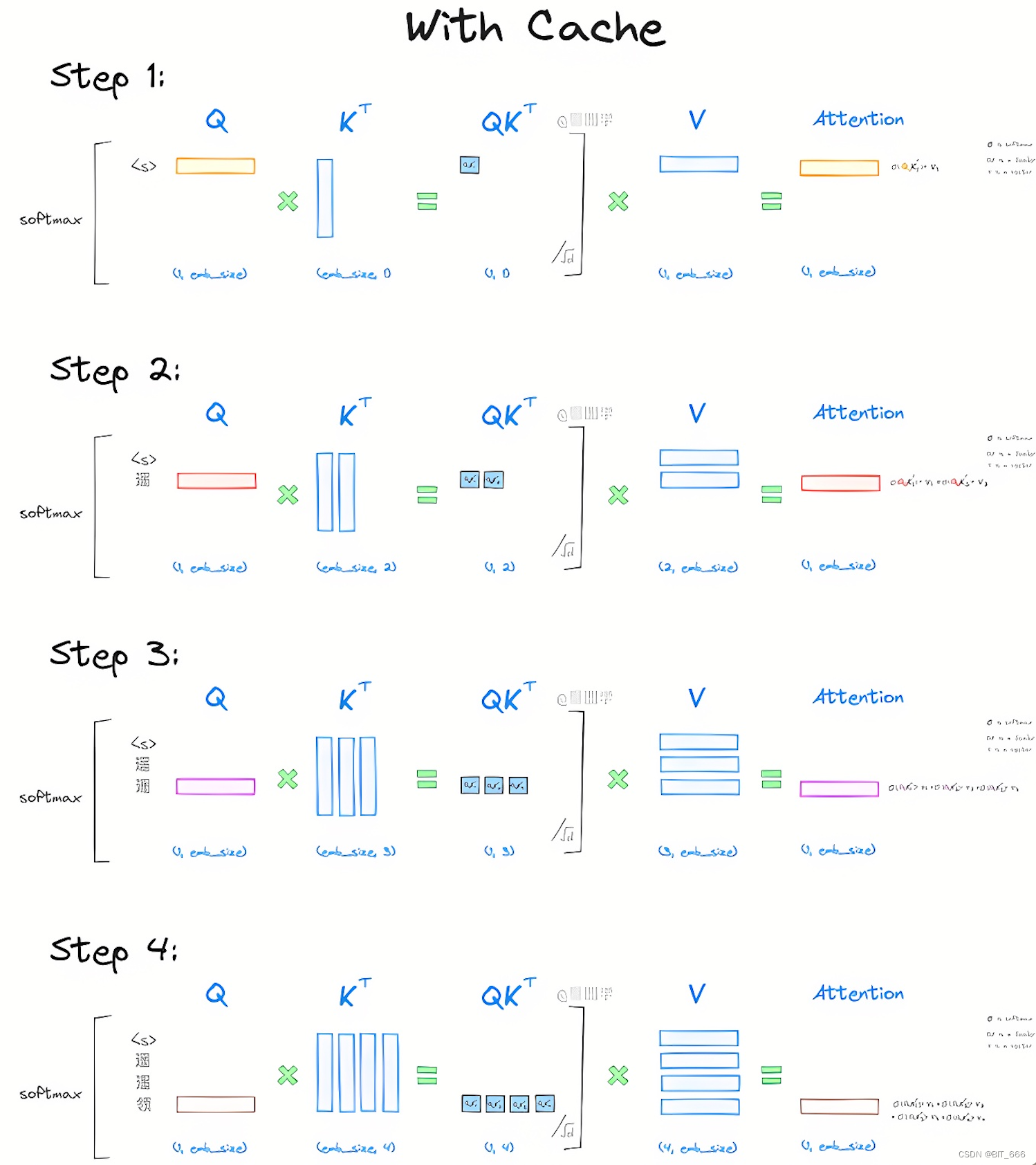
LLM Generate With KV Cache By GPT 2 llm kv cache CSDN
What Is Kv Cache - The pictures related to be able to What Is Kv Cache in the following paragraphs, hopefully they will can be useful and will increase your knowledge. Appreciate you for making the effort to be able to visit our website and even read our articles. Cya ~.
